第18期数智工作坊成功举办——探索计算传播学中的交叉学科研究实践
发布时间:2024-12-2511月5日下午,由中国人民大学国家治理大数据和人工智能创新平台(简称“创新平台”)与交叉科学研究院主办的第18期数智工作坊成功举行。本期工作坊主题为“交叉学科研究实践:以计算传播学研究的多模态数据为例”,特别邀请了中国人民大学新闻学院塔娜副教授,分享使用多模态数据开展的计算传播研究实践,探索如何有效地连接社会科学研究问题与算法、数据等要素。活动由创新平台代文林副主任主持,报告结束后,与会师生就相关议题展开了深入研讨。

主讲人简介

塔娜,中国人民大学新闻学院副教授,中国人民大学新闻与社会发展研究中心研究员,清华大学计算机科学与技术博士,美国加州大学戴维斯分校、香港中文大学访问学者。研究方向:计算与智能传播、新闻大数据、智能社会治理。承担科技部国家科技创新2030-重大专项项目子课题、国家自科基金青年项目、北京社科基金项目等,参与国家社科重大及多项省部级以上科研项目,主持或参与中宣部、中央网信办、国家体育总局多项部委委托项目。在计算机、传播学等学科核心期刊发表20余篇相关论文。
报告主要内容
1. 计算传播:问题引入

当前,计算传播学逐渐受到关注,但与之相关的“计算社会科学”概念更为人熟知。计算社会科学的起源可以追溯到2009年,当时一批学者在《Science》期刊上发表了一篇具有引领性和先导性的论文,正式提出了“计算社会科学”这一研究领域。
论文展示了一个著名的社会网络分析图,数据源自美国政治博客平台“Blogosphere”。通过根据政治立场对平台上的博主进行分群,直观地展示了博主间的互动关系。图中,红色和蓝色的博主群体分别代表不同的政治倾向,中间少量黄色节点则象征中立派。图形生动地揭示了当时美国政治形态的分化。论文作者总结,通过大规模的数据收集和分析,可以揭示个体和群体的行为特征。

在计算传播学领域,研究者关注的是传播学中能够通过计算方法进行探究的问题。例如,在舆论过程和舆情分析中,传统方法往往依赖人工标注。随着自然语言处理技术的发展,研究者可以利用情感分析和主题聚类等计算方法,自动分析在线舆情,识别互联网上的讨论主题及其情感分布。计算传播学强调“可计算性”,即研究的问题需要具备可量化或可计算的特性。传统传播学中的一些现象,如个体的自言自语等难以量化的传播行为,不适用于计算传播的研究范畴。计算传播学更关注可量化的指标,例如社交平台上的转发、点赞和评论数等,以及通过计算机视觉方法进行的研究。计算传播学的常用方法包括传播网络分析、文本挖掘、数据科学和人工智能新算法等。该领域的研究数据通常是非介入式采集,即数据的生产者在数据生成过程中并不意识到这些数据会被收集。使用该类方法需谨慎,避免侵犯隐私权和数据使用权。计算传播学的研究目标在于揭示传播行为背后的模式和法则。以传播学的经典理论“沉默的螺旋”为例,当某种观点在社会上占据主流地位时,持反对意见的一方往往会沉默甚至退出讨论。计算传播学可以通过分析社交平台的数据来验证这一现象。例如,研究者可以观察新闻点赞量的变化,来验证是否在点赞量显著上升后,反对意见的声音逐渐减少,从而形成“沉默效应”。这种验证方式展示了计算传播学在揭示传播行为规律方面的独特价值。
2. 案例分享:多模态传播数据的使用
(1) 文本型数据


塔娜老师首先分享了一个基于文本型数据的案例研究,深入探讨了搜索引擎的自动补全算法偏见问题。通过对搜索补全内容的分析,揭示了在搜索引擎中存在的性别、年龄和种族等偏见。研究发现,诸如“女司机”或“小学生”等群体在自动补全的提示中常伴有偏见性词汇,不仅揭示了搜索引擎在无意中强化了某些刻板印象,也反映了算法在处理用户数据时可能出现的价值偏向。为此,研究从社会科学视角引入了“算法偏见”和“数字不平等”等相关理论,进一步探讨这种偏见的形成原因以及可能的影响。
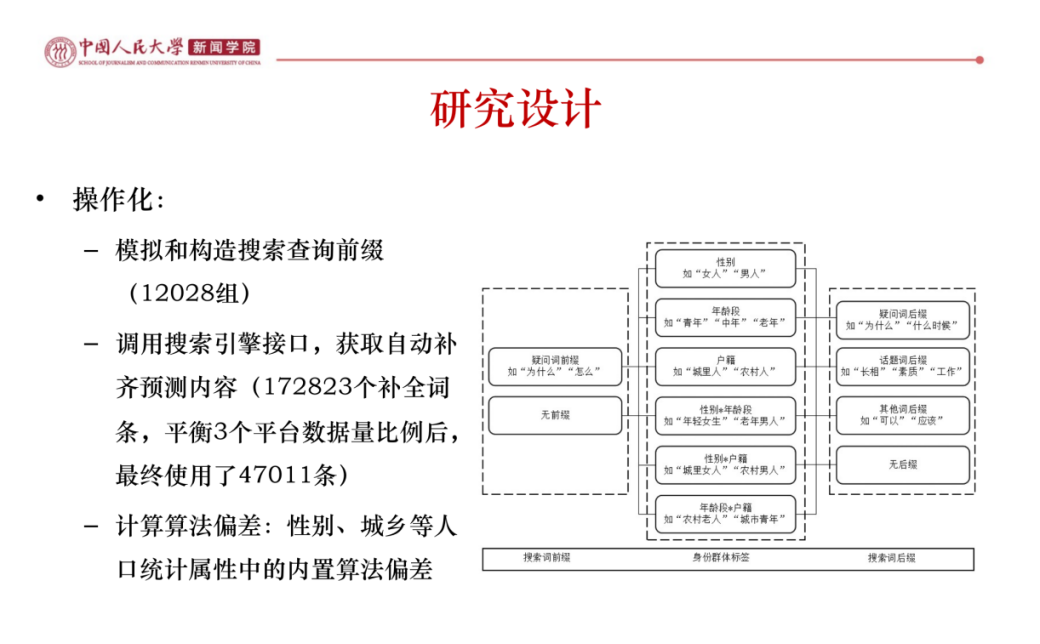

研究通过设置不同的搜索条件,收集了来自百度和谷歌的自动补全词汇,并利用Perspective API分析这些词汇的偏见程度。结果显示,女性、老年人和农村人口等群体的补全词条中偏见性词汇的出现频率明显高于男性、年轻人和城市居民。
此外,不同话题对偏见的影响存在差异,某些话题下的偏见程度更为显著。研究表明,虽然自动补全功能旨在便利用户搜索,但在无意间也可能助长负面偏见,突显了算法在数据应用过程中的潜在伦理问题。

数字弱势群体(如老年人)在搜索补全的内容中可能无意识地被赋予了负面的刻板印象,而这些群体自身并非数据的主要生产者。实验研究发现,暴露在含有歧视性补全词的环境下,用户在后续的招聘决策中更倾向于选择非受歧视群体。这表明,自动补全算法中的偏见可能会进一步强化用户的认知偏向,对算法设计和数字公平性提出了挑战和反思。
(2) 音频数据

第二个研究案例基于音频数据,分析了短视频平台抖音和TIKTOK中流行音乐的特征,并探讨了这些音乐为何具有“洗脑”效果。研究发现,尽管抖音平台的短视频内容非常个性化、分散化,但其背景音乐却高度集中,几首热门歌曲被广泛使用。研究团队收集了两个月的抖音热歌数据,去重后得到500多首歌曲样本,并对这些音乐的节拍特征、情感倾向、自相似度等进行了详细分析。结果表明,这些“洗脑神曲”通常具有高自相似度和强烈的情感特征,尤其是消极情感较为突出。

在探索性实验中,研究团队尝试将抖音热歌的特征与Spotify等其他音乐平台的流行趋势进行对比,发现抖音热歌的生命周期和情绪表达方式与Spotify上的歌曲有显著差异。抖音热歌生命周期较短,情感表达更为积极,人声比较多,且在结构上表现出较强的自相似度。
此外,平台在音乐内容推荐中的“平台化”作用也尤为明显。通过对比抖音热歌片段与原版歌曲,发现成为“热歌”的片段自相似度显著高于原版,这种特征在心理学上被称为“耳虫效应”,即旋律通过重复增强其吸引力。同时,抖音热歌的情感强度显著高于原版,这种强烈的情绪性使得这些歌曲更容易受到短视频用户的青睐。
(3) 图像数据


在新闻传播领域,国家形象研究一直是关注的重点。随着图像技术的发展,视觉传播已成为国家形象塑造的重要工具。本研究通过分析2016-2022年间十个具有不同政治立场的美国媒体账号在推特上发布的与中国相关图像,比较其与非中国相关图像在视觉特征上的差异。
研究分为两步展开。首先,计算并分析图像的视觉特征,包括饱和度、明亮度、色彩度和多样性等指标。其次,使用谷歌API接口对图像中的对象进行识别,将图像元素转化为文本形式,接着通过聚类分析来确定对象的主题类别,最后基于这些特征进行统计分析。


分析表明,美国媒体中涉及中国的图像通常呈现出饱和度低、色彩明亮、景深较小、构图复杂的特点。研究通过计算视觉技术识别图像中的视觉符号,如领导人、产业、疫情场景、军事符号和国旗等,并进一步分析这些符号对用户互动的影响。结果表明,负面情感的文本内容和低色彩度的图像更易激发用户互动。中国领导人、军事和国防相关图像较易获得用户点赞、评论或转发,而科技主题的图像则对用户的参与度产生负面影响。

美国媒体在社交平台上通过操纵审美特征和视觉符号来构建特定的中国国家形象。审美特征的操纵,如低饱和度和复杂构图,营造出一种不整齐的视觉印象。视觉符号的选择,如疫情中戴口罩的人群或街头杂乱场景,进一步突出了负面元素。这种视觉呈现影响了用户互动行为,也提示了平台用户互动机制对国家形象传播的潜在影响。
